【DeNA TechCon 2019】DeNAゲーム事業におけるデータエンジニアの貢献…客観性を担保したLTV予測やBigQuery運用におけるコスト最適化、そしてMLOpsへの挑戦

ディー・エヌ・エー(DeNA)<2432>は、2月6日、渋谷ヒカリエにて、技術者向けの大規模イベント「DeNA Technology Conference 2019」を開催した。
このイベントは、ゲームやエンタメのみならず、Eコマース、ソーシャルLIVE、ヘルスケア、オートモーティブ、そして横浜DeNAベイスターズのようなスポーツなど、様々な事業を展開し、さらに技術の力で事業の未来をリードするため、様々なチャレンジも行っているDeNAが、「多岐にわたるDeNAの技術的チャレンジに焦点を当て、広く世に公開することで、技術進歩・進化に役立つこと」を目的に、2016年より技術者向けに主催しているもの。
本記事では、「DeNAゲーム事業におけるデータエンジニアの貢献」と題したセッションをレポートする。
■分析部とデータエンジニアの紹介

DeNAの分析部は、事業における意思決定の質を最大限に高めるための部門で、より高度な分析を低コストで実現するために、BigQueryを中心としたデータ分析基盤を活用している。
「DeNAゲーム事業におけるデータエンジニアの貢献」と題した本セッションでは、"DeNAのゲーム事業における意思決定を分析部がどのように支えているか"と"データ分析基盤を運用する中でぶつかった課題をどのように乗り越えてきたか"について、同社分析部の岩尾一優氏、石川勇氏が、技術的な側面から実例を交えて紹介していった。
まず、ゲームサービス事業部 分析部について岩尾氏が紹介。分析部はゲーム事業における意思決定の支援をするのが役割で、例えばゲーム内施策の立案のサポートや振り返り、それから事業計画立案のサポートを行う組織とのこと。
意思決定の支援という意味合いでは、主にデータアナリストが役割を担うが、我々データエンジニア、データサイエンティストも所属しており、同じ分析部内にこれらの役割が所属するというところで効率的に活動を進めているという。
そして、DeNA分析部の特徴について、「データエンジニアはアナリストと仕事することでゲームのドメイン知識も自然と溜まる。逆にアナリスト、サイエンティストもエンジニアと仕事することで技術力の強化ができている」(岩尾)と紹介した。

岩尾氏曰く、データエンジニアの役割を細分化すると、事業に対して直接付加価値を与えるような活動をする事業系の役割、そして作成したシステムを保守、改善していくという役割もあるという。そこで本セッションは第1部で事業系と保守系、そして第2部で改善系の2部構成で行われた。
■客観性を担保し、安定的に利便性高くLTV予測を提供する手法とは
まず第1部では、石川氏が登壇し、"LTV予測による事業への貢献~エンジニアによるビジネス意思決定サポート事例~"をテーマに話を進めた。

▲分析部の石川勇氏。
始めにLTVの重要性について触れた石川氏。一般的なLTVの定義は、顧客生涯価値、平たく言うとサービスと関係する中で顧客が支払うお金の総額となる。
これをゲーム事業に当てはめると、サービス開始から終了までにプレイヤーが支払う総額という定義だ。ただ「1人あたりの金額、というのが曲者」と石川氏。ゲーム事業では、「月額購入や都度課金など商品の買いかたなど多種多様。また、商品を買わなくても楽しんでもらいたいという無料サービスの側面もあり、1人あたりの平均金額というものはかなり予測しずらい」(石川)という。
石川氏は「LTVの数字は、広告やCMにいくらかけるかを判断する直接の数字となっており、計算する必要性がある」として、一例としてゲーム事業における宣伝広告費で、DeNAでは3ヵ月間で30憶円程度になるとのことだ。
LTVの事業的な重要性を説明したところで、実際どのようにLTVが使われているかを石川氏が説明。
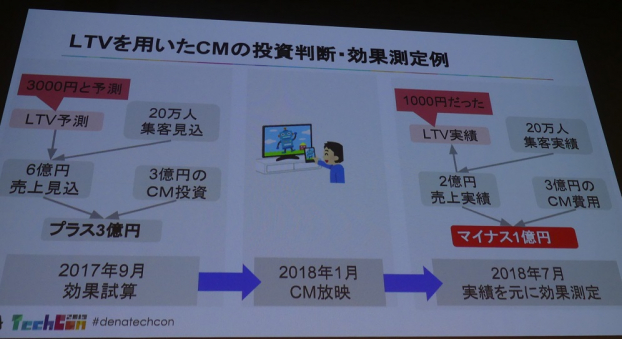
まずは仮のケースとして、LTVを用いたCMの投資判断・効果測定例の図(上)を元に、1つのCMで数億円を使った投資判断について、LTV予測を極端に外した例を紹介した石川氏。
CM費用が3憶円かかるとして、その投資判断する場合に売上の見込みを計算するのが通例。このケースではCMで20万人がゲームを開始して、LTVが3000円と予測している。つまり6憶円の売上増加が見込めるという予測だ。
ところが蓋を開ければ20万人がゲームに入ってきたが、想定に反して実際は売上が2憶円しか増えておらず、CMとしては1憶円の損失という例だ。
石川氏は「実際のLTVが1000円だったため、3000円の予測が高すぎた」ことがこの例での失敗の要因と説明。このように特定の機会に流入してくる顧客のLTVを予測するニーズは高く、予測を外したときに事業に与えるインパクトが大きいことがわかった。
このように重要な事業判断の要素となるLTVだが、これまでどのような課題があったのか? まずLTV予測では、インストール時期ごとにプレイヤーの熱量やゲームの仕様が異なるため、インストール時期を起点に算出していた。また、顧客生涯価値としながらも一律に比較するために180日など一定の期間で区切っていた。以下がその具体的な手順。
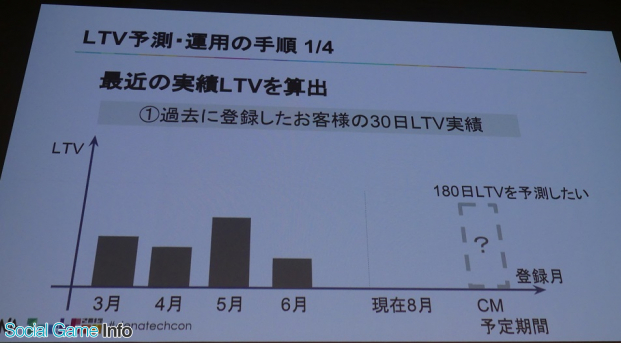
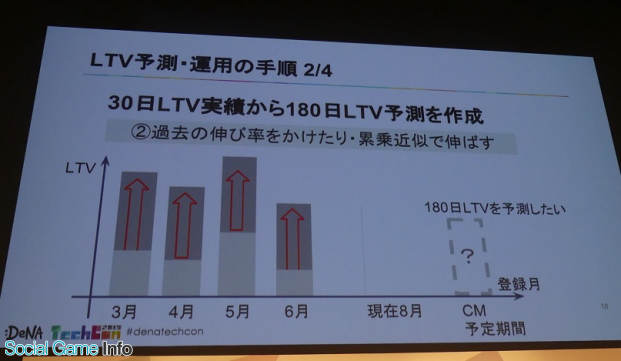
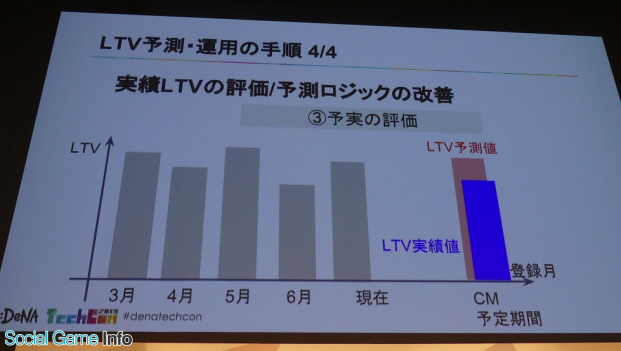
このように、180日LTVを予測したい場合、まずは月ごとに登録したプレイヤーのLTVの平均値、現在が8月だとしたら最も最近のゲーム仕様のLTVを参照したいためまずは、3月~6月のプレイヤーのデータを実績として算出していた。ここで気づくのが、どの期間のプレイヤーも180日間遊んでいない点。これはこの後をどう予測するのか?
「従来は過去の30日LTV実績を、180日LTV相当に伸ばす作業がまず必要だった」(石川)そうだ。
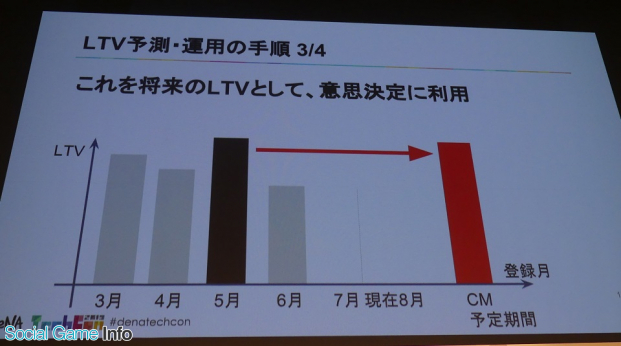
最後にCM対象月と近い条件の月などからCM時の予測LTVとして出していた。この予測された180日LTVを1年以上経過した後に、本当の実績と比較しながら、予測手法について振り返ることになる。
では、なぜこのような予測方法なのか? 実はそこがLTV予測の難しさを表していた。
ゲーム事業ではプレイヤーの平均像というのもがなく、石川氏は「過去の実績を元に未来を予測する際、未来のプレイヤーが過去と同じであればもっと色々な方法があるが、過去と異なる可能性が非常に高い」と語る。また、ゲーム側もその内容が変わってくる場合もある。
「運用計画はあっても、実現の程度がよくわからなかったり、臨機応変な運用をするために未来の情報はないと考えて良い状態。そういったものを考慮項目としているが、プレイヤーもゲームコンテンツも変わる中で、さらに金曜日や年末に入ったプレイヤーはじっくり遊んでくれそうといった、時期に関連した考慮項目が過去の手法では区別できていなかった」(石川)。それがLTV予測の本質的な難しさになっているのこと。
続いて石川氏は、予測の改善サイクルについて紹介。実は予測LTVについて、DeNAで過去に何度かプロジェクトが立ち上がっていたそうで、対策してきた中で周辺の課題自体は見えていたという。
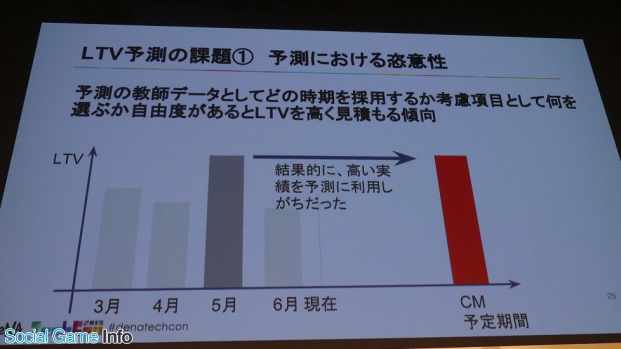
1つ目の課題は恣意性。実はトータルで過去の色々なCMを振り返ってみたとき、「予測LTVがなぜか高く見積もられる傾向があった」と石川氏。「先程話にあった年末や金曜日のLTVが高いというトレンドを考慮項目としながらも、実はわからないと言われていた運用項目や、運用予定の希望的観測も予測に含まれがちになるのが原因だった」と続けた。
このような定義できない考慮項目を選択するしかない手順が課題としてあり、LTVの見積もりが高くなってしまう傾向は判断を見誤ることにつながるため、恣意性を排除する必要がある。
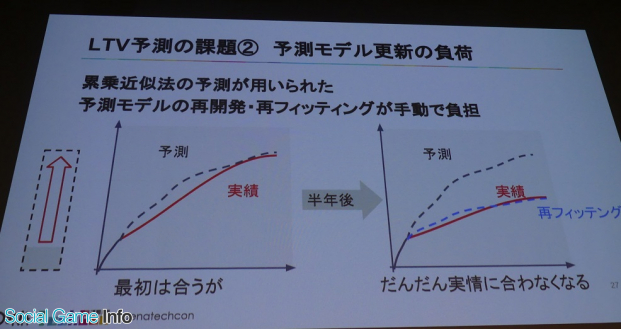
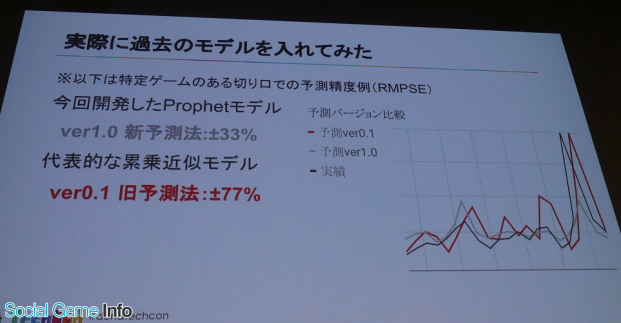
次の課題は予測モデル更新の負荷。これまで伸び率を算出する方法として累乗近似などのモデルが用いられていたが、係数はフィッテイングした後もしばらくは使えるが半年後、1年後になると段々外れてきてレガシー化してくるため予測モデルの再開発、再フィッテイングが必要だがそれが大きな負担となっていた。

3つ目の課題は、予実評価の難しさ。予測LTVは担当者に依頼しないと手に入らなかったが、実績が出るのが半年~1年後のため、その間に予測担当者が異動や退職する場合もあり、過去のサンプリ期間や考慮項目、予測モデルのバージョンの組み合わせがわからなくなることが頻繁にあった。
そして石川氏は、これらの課題を1つ1つ解決していった。
まず、予測LTV作成に恣意性が入り得るという課題については、サンプリング期間、考慮項目(トレンドと周期)を固定し、まずどこかの月を選ぶという作業をしないこと、すべての数字、データを使うことに決めたという。それから考慮する項目についても予測で使う項目は限定し、考慮の難しい顧客の傾向やゲーム内施策を選択しなくて済むようにしたとのこと。
この2点を決めたうえで予測改善プロジェクトを立ち上げ、データサイエンティストとチームを組んで、ほかの業務を進めながら2ヶ月でプロジェクトを完成。石川氏はその過程について触れ、Prophetという既存の時系列取得モデルについて紹介した。
Prophetはpythonで利用できる簡単なライブラリ。ライブラリ側でモデルの学習が行われ、学習したモデルが将来のLTV予測値を出力。これにより実際に恣意性を排除した予測を完成させた。
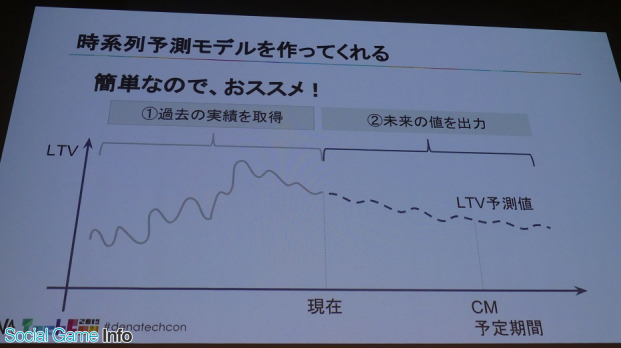
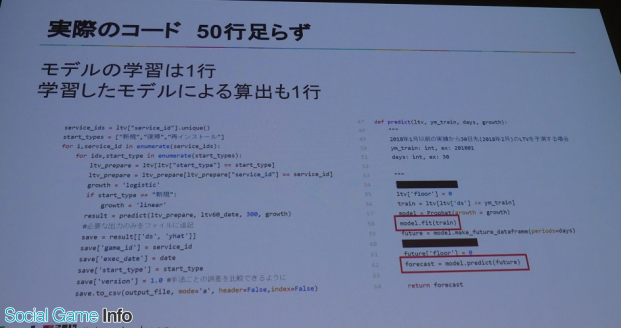
予測モデル更新の運用が手間という課題については、MLモデル on VM+Jenkinsで「モデルの更新+推論」を自動化して解決。予測モデルのタスクは開発(Prophetというモデルを選定、検証解釈する)、更新(Ptophetのモデルを学習する、またはしなおす)、適用(学習済みモデルで実際の予測をする)の3つに分類されている。
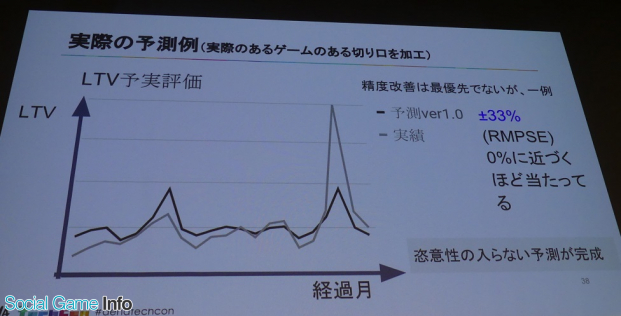
これにより、過去の累乗近似では更新が面倒だったが、Prophetで時系列予測に置き換えたことで更新、適用が高速化され、毎朝最新の予測を算出できるなど完全な自動化に成功した。

3つ目の予測LTV提供に時間がかかる予測と実績の評価ができないという課題については、BIツールで最新の予測結果を提供、過去の予測と実績も一括で提供でき、改善・効率化された。
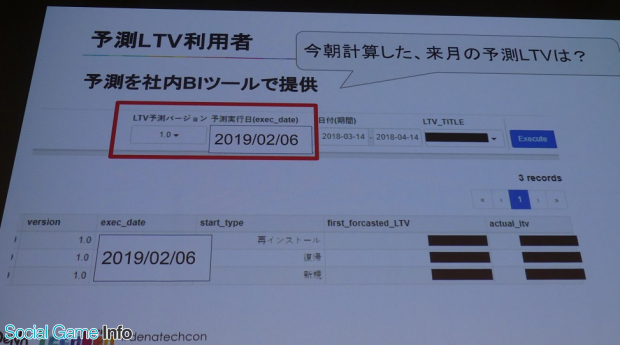

最後に石川氏は、「過去のプロジェクトが抱えた課題を解決し、これにより客観性が担保され、安定的に利便性高く予測を提供できるようになった」と第一部をまとめ、全社的なクラウド移行が予定されていることなど、今後の展望について紹介した。

■BigQuery運用のコスト最適化、その事例に迫る
続いて第2部"システム運用の改善"は、分析部の3つの役割の中の改善系がテーマ。BigQueryの運用におけるコスト最適化やMLOpsへの挑戦といった裏で動いているシステム、特に運用周りにおける課題とその解決策について、岩尾氏が解説していった。

▲分析部のデータエンジニアリンググループのグループリーダーを担当する岩尾一優氏。
昨年7月にDeNAにジョインした岩尾氏は、「入社以来、ずっとBigQuery周りのコストの事が気になっていた」と、ただ規模が大きいだけでなく秩序が乱れているように感じたそうで、現在"BQ警察"としてコスト最適化に注力している。
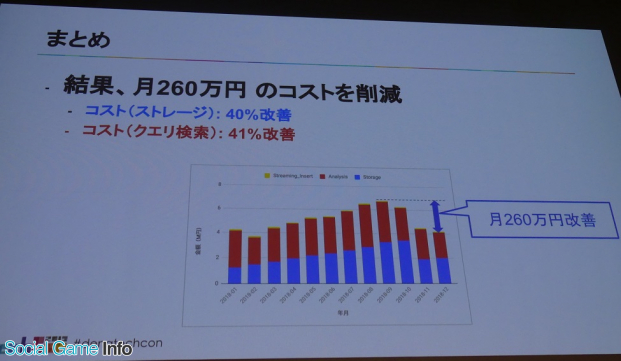
始めに岩尾氏は、DeNAゲーム事業でどれくらいの規模のデータを扱っているか数値で示し、BigQueryのストレージ容量が2PB以上、BigQueryのコスト(2018年9月時点)が月680万円かかっていると説明。「これはかなり大きい部類のデータとコスト」(岩尾)だが、それが12月の時点で420万円になったという。

その3ヵ月間でコストを削減した過程で何を行ったのか? 岩尾氏は大きく分けて3つあるとし、その1つが現状の可視化。請求データを使って全体を見た後に、BigQueryのメタデータを見て何にどれくらいかかっているのかを可視化したそうだ。
可視化によって攻め所がわかってきたので、次にシステム的な改善に着手。ここで岩尾氏は、「BigQueryはスキャンしたデータ量によって従量課金である」という特徴を紹介し、この点が重要なトピックスとした。
3点目は運用の改善。そもそも巨大なクエリを投げてしまったときに気づく仕組みがこれまでなかったという背景があり、そこを気付ける仕組みを導入し、気づきの後にメンバー間で改善するマインド醸成に取り組んだという。


▲採用した主な技術を紹介。
現状の可視化(請求データ)について、2018年1月~9月の期間、どのようにコストが推移しているのか現したグラフが提示され、「ストレージもクエリ検索もコスト増加傾向で、3ヵ月ごとに月額で100万円ほど伸びている」と解説した岩尾氏。
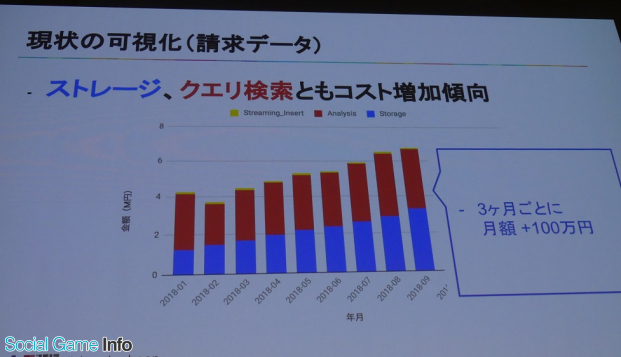
その詳細を確認するために利用されたのが、Stackdriver Monitoring。これは専門的な知識がなくても簡単な操作でGCPやAWSのリソースと連携してメタデータを可視化できるという。「我々の使い方では、BigQueryのメタデータ(ストレージ容量やクエリ検索量)の見える化に利用している」(岩尾)とのこと。
ストレージ容量の内訳を確認する際、あるゲームでは特定のデータセットがストレージの大半を占めていることなどがわかるという。その部分を削減することができれば「ストレージ容量が大幅に削減できそうだなというあたりを付けることができる」と岩尾氏は語った。

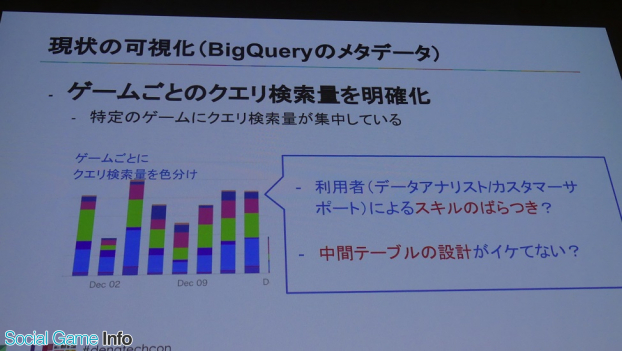
そしてクエリについては、ゲームごとのクエリ検索量を色分けして明確化した。これで、ある部分が全体の大部分を占めていることがわかる。
「ゲーム自体は十数タイトル管理しているが、その中でもいくつかのタイトルだけに集中していることが見てとれます。もちろんデータの保存量自体バラつきはあり、これで一概に良い悪いは言えません。利用者によるスキルのバラつきや、そもそも検索対象となっている中間テーブルの設計に問題があるのかも」という部分にも踏み込んだと岩尾氏は語った。
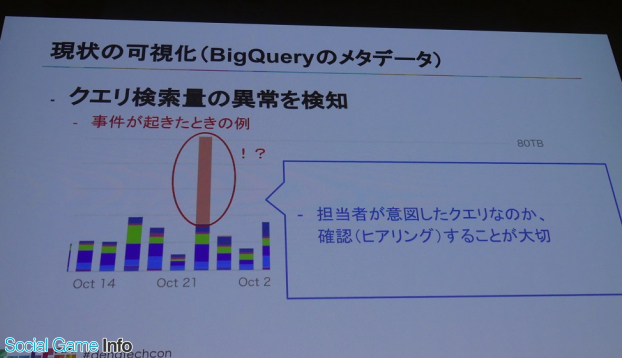
また、別の切り口として、ある日、クエリが1日に50TBくらい投げられた事件が発生した事例を紹介。これも可視化することにより、担当者が意図していたクエリかどうか、その原因を調べることができるなど対策の検討がしやすいという。
ここまでが現状の可視化について。次に岩尾氏は5つの改善事例を紹介。
1つ目は、データライフサイクルの定義することでストレージ容量を削減した改善事例。データ分析は本来1日だけ保存しておけばいい場合や、ずっと残しておきたいなど、必要な保存期間が異なる。ただ、「リリース時にそれが確実にわかるかと言えばいえばそうではない」と岩尾氏。
そこで重要なのが定期的な棚卸。「我々はデータアナリストと同じ部内にいるので、連携しながらこれは消していいのかどうか棚卸しながら設計しました」(岩尾)とし、必要な保存期間に応じてローテーションさせる仕組みを導入した。
そして設定ファイル上で、どのプロジェクト、どのデータセットでどのテーブルを何日間保存したいのかを一元管理した。一つのプロジェクトだけではなく、全体でどんな感じで設定されているか一元管理することで、検討漏れがなくなる。あるゲームタイトルでは約60%のストレージ容量を削減できたそうだ。
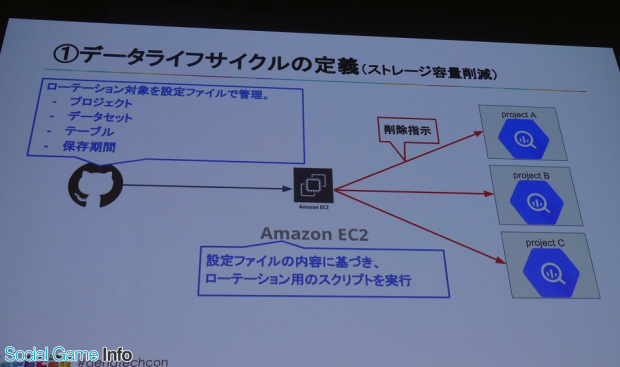
※一部AWSを利用しているのはシステム移行中のため
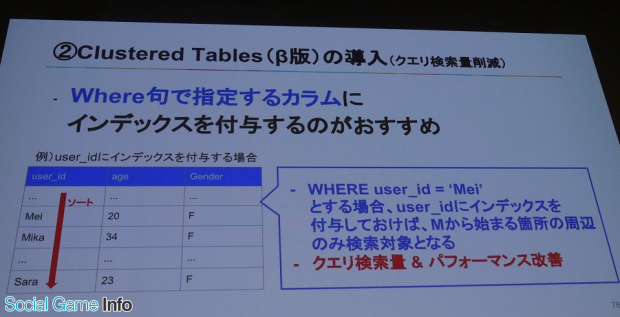
2点目の改善策は、Clusterd Tables(β版)を導入したクエリ検索量の削減。これまでBigQueryは分割テーブルを使って検索量を抑えていたがそうだが、一方で日付レベルよりさらに絞り込む方法はなかったという。
そこで、「他のカラムについてもインデックス付与することにより、ある程度検索範囲を絞れる機能を導入した」と岩尾氏。実際にこれまで1回で2TB検索しなければいけなかったものが、2GBまで抑えられたという例もあったそうだ。
また、移行については新規テーブルを作成し、既存テーブルからレコードをコピーするので面倒ながらも、「そこさえ乗り越えればかなりの恩恵がある」(岩尾)とのこと。
3点目はjsonペイロードのparseによるクエリ検索量削減。ユーザーが保持しているアイテムの1~100から1だけを抜き出したい場合でも、これまではjsonペイロード全体を検索してしまい、クエリ検索量の増加につながってしまっていた。そこで、よく使うデータはparseして別のカラムとして保持して検索するのがクエリ検索量削減になるそうだ。

4点目は、BIツールの不要な定期実行機能を停止することでのクエリ検索量の削減。岩尾氏は「我々は、使っているBIツールをcron形式で行っていたので、それに慣れていないデータアナリストであれば、不用意に週末だったり夜間を実行してしまうことがあった」と説明し、その点も改善した。

最後の改善事例は、巨大クエリ実行時にSlack通知をする仕組みを作ったこと。
岩尾氏によると、システム的にガードをかけることも可能だそうだが、「本当に必要なクエリをたたくときにエラーが返ってきたら、イラっとすると思う。システム的ガードではなく敢えてメンバーを信頼し、巨大クエリを投げてしまっても通知を見て皆でどうすれば良かったか話し合える文化をつくりたかった」とのこと。
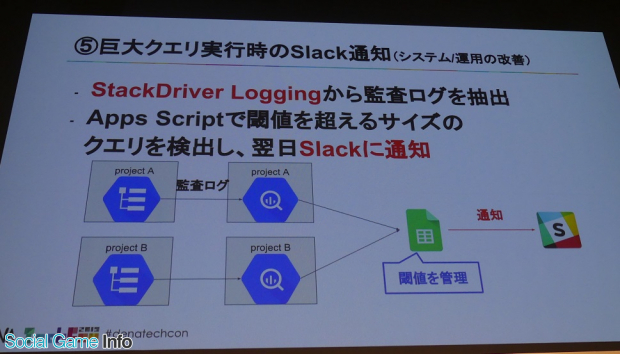
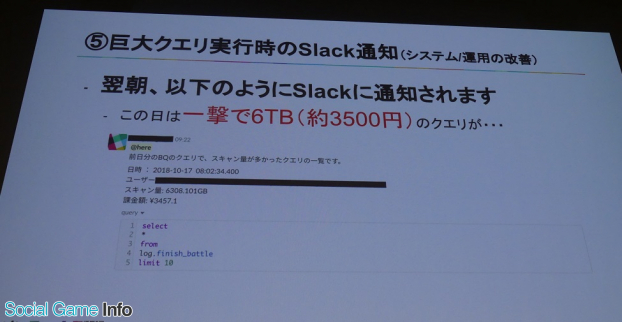
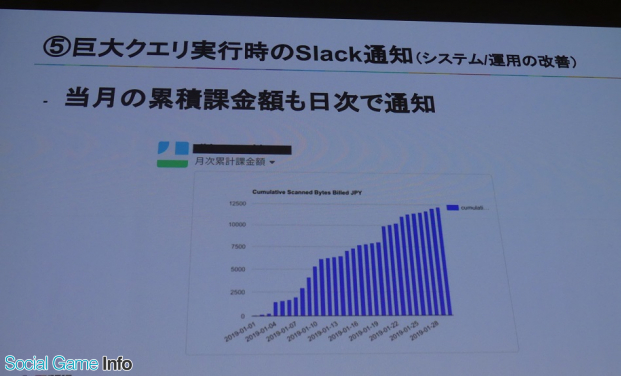
そして岩尾氏は、紹介した改善事例にって、結果的に月260万円のコストを削減し、ストレージは40%、クエリ検索は41%改善したことを明かした。
■MLOpsへの挑戦、今後のデータエンジニアリンググループの展望
最後にMLOpsへの取り組みについて紹介した岩尾氏。
伝えたいこととして、「初心者にとってMLモデルの実行はハードルが高いです。部内のデータサイエンティストがJupyter Notebookで作成したMLモデルをgithubなどで経由してやり取りしていたが、それだと自分の環境だけ動かないみたいなことも発生してします。環境構築ほどイライラする作業はないと思っている」とそれを解決したいと考えたのが取り組みへのキッカケだそうだ。

従来のシステムは、VM上にMLモデルの設置、実行をしていたが、この構成だと環境構築が面倒で、今後の移行も困難だという。そこでBigQuery、Dockerに加え、ContainerRegistryという主な技術を活かし、「dockerコンテナで起動するよう変更した」(岩尾氏)という。
それによる新しいシステム構成では、EC2上でdockerコンテナを起動する方式を採用。Container Registryから必要なDockerイメージをpullして使うだけで環境構築が簡単で、GCP移行時もGCEでdocker runするだけの容易さがメリットのようだ。

※一部AWSを利用しているのはシステム移行中のため
岩尾氏は、「これまでデータ分析におけるMLの導入は環境構築や移行の手間に悩まされてきたが、MLモデルをdockerコンテナを入れたことで解決に向かっている」とML Opsの現状に触れたが、「まだまだ未解決な部分もある」とし、今後の展開として、現在ローカルで行っているDockerイメージのビルドを自動化したり、もしくは学習・推論でモジュールを分割すること、モデルのバージョン管理、ロギングについて、「現在対応をしている最中」とコメントした。
そして最後に、「データエンジニアリンググループは2月から出来たばかりの組織です。本日お話した内容以外にも色々行っています。現在立ち上げ期ですので、我こそはというデータエンジニアの方はジョインして一緒に盛り上げていきましょう」とメッセージを送った。





会社情報
- 会社名
- 株式会社ディー・エヌ・エー(DeNA)
- 設立
- 1999年3月
- 代表者
- 代表取締役会長 南場 智子/代表取締役社長兼CEO 岡村 信悟
- 決算期
- 3月
- 直近業績
- 売上収益1349億1400万円、営業利益42億0200万円、税引前利益135億9500万円、最終利益88億5700万円(2023年3月期)
- 上場区分
- 東証プライム
- 証券コード
- 2432